Shifting OffSec Left
with Agentic AI
From reactive scanning to continuous offensive validation. Why shifting scanners left did not shift attacker-like testing left, and what a credible path forward looks like.
01 · The AppSec Gap
We shifted scanners left.
We didn't shift the attacker's mindset left.
Over the past decade, security teams invested heavily in shifting left. SAST, DAST, software composition analysis, secret scanning, dependency monitoring, bug bounty: each promised to catch issues earlier in the software development lifecycle. Budgets grew, tooling matured, and dashboards filled up with findings.
And yet, year after year, the same pattern repeats. The important vulnerabilities, the ones that cause breaches, regulatory fines, and front-page headlines, continue to be discovered late. They are found by external researchers, third-party pentesters engaged once a year, or by the attackers themselves. Somewhere between the thousands of low-confidence alerts and the quarterly pentest report, real risk is slipping through.
The pattern is not a tooling gap. It is a category gap. The tools we shifted left are pattern-matching systems. They are excellent at signature-driven checks, dependency versions, and known-bad inputs. What they cannot do, structurally, is reason about what an application is actually doing.
Noise
Hundreds to thousands of findings, low signal-to-noise, expensive to triage.
Late
Meaningful validation still lands near release, when fixes are most expensive.
Blind
Logic flaws, authorisation bypasses and chained attacks are routinely missed.
Reactive
Security becomes a reporting function instead of an engineering feedback loop.
How most tools operate vs. how attackers actually work
How most tools operate
Pattern matching against known bad inputs
Rule execution and payload spraying
Checklist coverage over exploit reasoning
Findings first, proof later (or never)
Treat every form field the same
What attackers actually do
Understand intent and workflow
Track state, roles and ownership
Chain weak signals into real impact
Adapt when a path fails, try a different angle
Go where the business value is concentrated
The shift-left movement optimised for one half of the problem, moving detection earlier, and quietly assumed the other half, moving attacker-like validation earlier, would follow on its own. It didn't. The categories that matter most to a business are exactly the categories that pattern-matching tools cannot reach.
01
Business logic
Discount abuse, approval bypass, sequence manipulation, workflow edge cases. Context-dependent by definition.
02
Authorisation
IDORs, broken role boundaries, tenant crossover, privilege escalation. The bugs that leak entire customer databases.
03
Attack chains
Low-severity issues combined into material business impact. Individually triaged as noise; together, a breach.
02 · Trust and Assurance
The industry already knows what good testing looks like. It just assumes a human is doing it.
Penetration testing is not a greenfield discipline. Standards bodies, certification schemes and accreditation frameworks like CREST have spent years codifying what trustworthy offensive testing requires. These frameworks exist for a reason: they were built in response to the reality that security assurance claims without supporting evidence are indistinguishable from marketing.
The problem is that nearly every formal definition of good testing assumes a certified human being is the one doing the work. The professional ethics, the personal accountability, the ability to reason about scope, the discipline to document, the judgement to know when to stop: all of this is an attribute of the tester, not the tool.
When an AI system is dropped into that seat, the assumptions break.
What good testing requires
Evidence-based reporting, not assertion-based
Reproducible findings with clear steps
Clear scope and constraint handling
Honest accounting of what was and was not tested
Auditability and full activity logging
What breaks with naive AI tools
No certification or personal accountability
No professional ethics to suppress fabrication
No guarantee the system is reasoning rather than scanning
Confident-sounding output can still be entirely wrong
Hallucinated findings are the new false positive
The right question to ask any automated pentesting system is simple: does it behave like a pentester, or does it just sound like one?
Answering that question honestly requires a more rigorous evaluation lens than the one the industry typically uses to judge scanners. Counting findings doesn't work. Coverage metrics against known-bad-input lists don't work. What works is a first-principles rubric that measures whether the system is doing the things a pentester does, in the way a pentester does them.
Five first-principles criteria for evaluating offensive AI
Ground truth
Can the system prove the issue exists and reproduce it, rather than merely claim it?
Intentional reasoning
Is it adapting to what it observes, or just executing a checklist dressed up as intelligence?
State awareness
Does it understand sessions, roles, ownership and workflow position, or does it treat every request in isolation?
Constraint compliance
Does it stay in scope, operate safely, and respect the rules of engagement, even when reasoning pulls it elsewhere?
Human verifiability
Can a qualified tester audit, replay and independently confirm what the system did and why?
All five, together
If any one of these fails, the result may be useful automation, but it is not penetration testing.
03 · The Clock Is Moving
The gap between discovery and weaponisation is collapsing to hours.
This is not a hypothetical acceleration. Public research, including the recent Mythos-ready work on autonomous offensive capability, documents a clear trend: the time between a vulnerability becoming known and a working exploit being available is shrinking, and it is shrinking because the attacker's half of the equation is automating faster than the defender's.
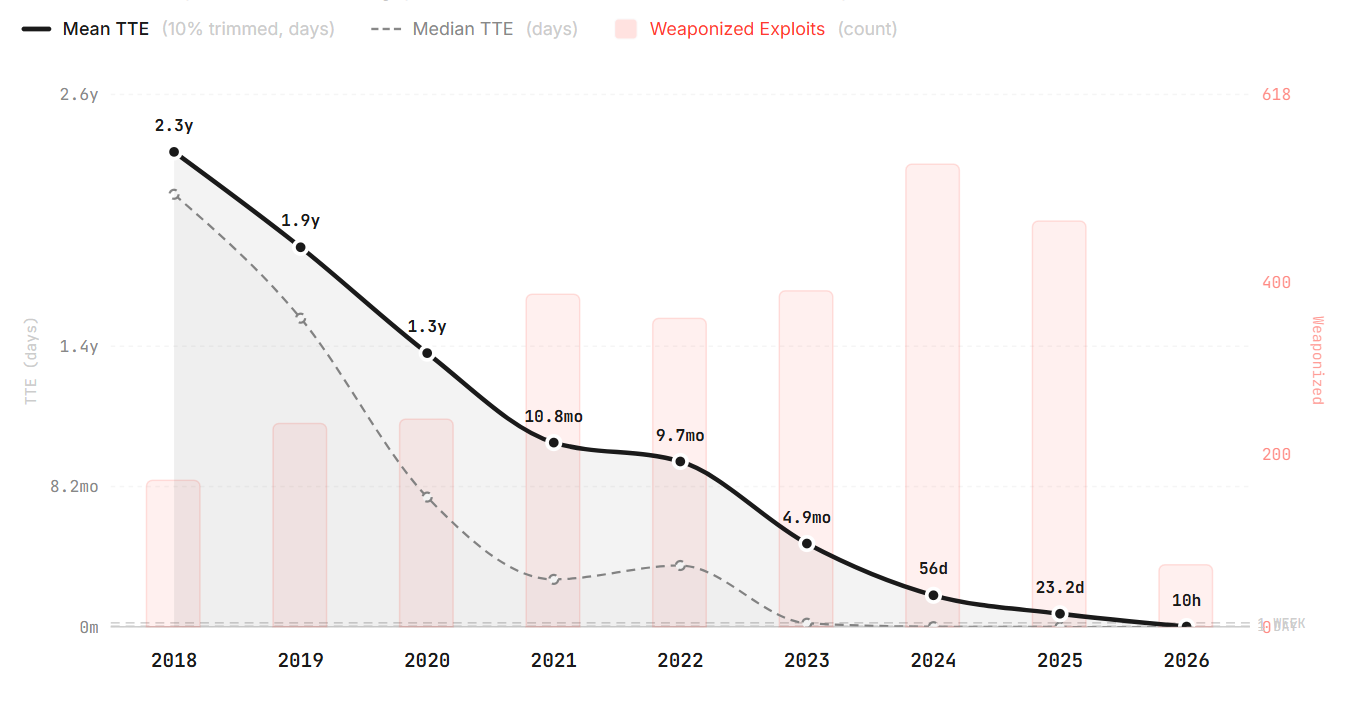
Chart from the Zero Day Clock, by Sergej Epp. Time-to-Exploit has collapsed from years to hours over the past decade. Based on 3,529 CVE-exploit pairs from CISA KEV, VulnCheck KEV and XDB.
Several forces are converging:
→
AI-driven vulnerability discovery is accelerating rapidly and generalising across codebases.
→
Exploit development, historically a bottleneck, is becoming autonomous.
→
Attackers gain a structural speed advantage that compounds over every release cycle.
→
Traditional patch-and-validation cycles were designed for a much slower adversary.
The practical consequence of this shift is stark: defenders operating at human speed are now trying to keep up with attackers operating at machine speed. Annual pentests, quarterly red team engagements, and once-per-release security reviews were designed for a world where exploit development took weeks. That world is not the world we ship software into anymore.
The defender's asymmetry
Defenders today
Manual triage and late validation
Point-in-time testing tied to release gates
Snapshot visibility of a continuously changing target
Feedback loops measured in weeks, not hours
What we actually need
Attacker-like validation before production
Continuous offensive testing on every meaningful change
Evidence-first output engineers can act on immediately
Feedback loops measured in minutes
04 · The Agentic Alternative
From "does this look vulnerable?"
to "can I actually break this?"
Agentic AI in offensive security is a different category from the AI features being retrofitted onto legacy scanners. It is not an LLM summarising scan output. It is not a prompt that asks a model to "find vulnerabilities" in a file. Those approaches import the weaknesses of the underlying tools and add hallucination risk on top.
An agentic system, in the sense that matters here, is one that can operate autonomously inside a loop: observe the target, form a hypothesis about what might be wrong, act on that hypothesis with a concrete test, observe the response, update its understanding, and decide what to do next. That loop is the thing human pentesters run in their heads for days at a time.
The shift in question changes from does this look vulnerable?, which is a pattern-recognition question, to can I actually break this?, which is an empirical question. The latter produces proof. The former produces alerts.
PHASE 01
Explore
Map the attack surface, authenticated paths, roles and trust boundaries the way a user and a tester would, not the way a crawler does.
PHASE 02
Reason
Form hypotheses about what is likely to break, adapt to what the application returns, and prioritise paths that lead to high-value impact.
PHASE 03
Prove
Validate exploitability with reproducible, non-destructive evidence, so findings ship with the proof a fix-and-retest workflow needs.
The goal is the same offensive chain of reasoning a skilled human tester runs. The difference is that it runs much faster, and much more often.
05 · The Operating Model
Scope, Recon, Plan, Execute, Report, Retest.
An agentic offensive system that can be trusted in the SDLC is not a one-shot scan. It runs the same six-phase loop a credible human engagement would run, and it produces the same kinds of artefacts at each phase, so the output survives review.
01
Scope
Good scope is the foundation of high signal
An autonomous pentest is only as credible as the scope it operates within. A well-defined scope removes ambiguity for the system, encodes the rules of engagement, and gives security teams a concrete audit surface.
›
Domains, APIs, mobile apps, tenants and environment selection
›
Role-aware accounts and authentication context for each role in the system
›
Rate limits, prohibited actions, and data handling rules
›
An executable scope file that can be reused unchanged in CI/CD runs
02
Recon
Recon builds the map the rest of the test operates on
Before planning any attack, the system enumerates what is actually there: the reachable functionality, the authentication mechanics, the session semantics, and the technology fingerprint. This is the phase most scanners skip or treat as incidental, and it is the reason they miss state-dependent issues.
›
Enumerates reachable functionality, parameters and workflow paths
›
Learns tokens, cookies, CSRF mechanisms, refresh flows and error handling
›
Fingerprints the stack to choose relevant test strategies, not generic payloads
›
Produces an attack-surface graph that can be diffed against in future runs
03
Plan
Planning turns surface area into testable hypotheses
The system doesn't test everything the same way. Planning is where surface area becomes a prioritised list of hypotheses, each with an expected impact and a chosen approach. This is the step that separates goal-driven testing from spray-and-pray payload execution.
›
Choose tests based on components, data flows and state transitions
›
Set concrete objectives: what impact are we trying to prove?
›
Decide which roles and workflow transitions actually matter
›
Do safe checks first, then deeper validation where the evidence justifies it
04
Execute
Execution is goal-driven, not spray-and-pray
Execution is where most automation falls apart, because real applications are stateful, asynchronous, and full of edge cases that invalidate naive fuzzing. Goal-driven execution holds the plan, but recovers and adapts when reality diverges from it.
›
Handles login, navigation, multi-step workflows and asynchronous jobs
›
Maintains sessions, CSRF tokens, pagination and error recovery
›
Respects operational limits and stop conditions at all times
›
Captures everything engineering needs: requests, responses, context and timestamps
05
Report
Reports should be ticket-ready, not PDF-ware
A report is not the end of the engagement, it is the start of the remediation cycle. A report that an engineer cannot act on without a meeting is a report that will not get acted on quickly. Every finding should answer three questions at minimum: what is wrong, where is it, and why does it matter.
›
Safe, explicit reproduction steps, with evidence of real impact
›
Output into the tools engineering already uses: Jira, GitHub, CI artefacts, dashboards
›
Machine-readable formats (SARIF/JSON) for downstream automation
›
Remediation guidance tied to the specific finding, not boilerplate
06
Retest
Retest on demand closes the loop
The single most common failure mode in pentest programmes is the gap between "fix merged" and "fix verified". Retest-on-demand turns that gap from weeks into minutes and forces confirmation that an issue is actually resolved rather than only masked.
›
Trigger from a fix commit, ticket transition or release build
›
Confirm the original issue is resolved, not merely no longer reachable by the same path
›
Run targeted regression to check that the fix has not introduced new risk
›
Produce a clear before-and-after evidence trail for audit and compliance
06 · Where Agentic AI Adds Value Early
The strongest systems find the categories traditional tooling struggles with most.
It is worth being precise about where agentic testing earns its place in an AppSec programme, and where it doesn't. The existing stack is not going away. SAST still catches unsafe patterns at commit time. SCA still flags vulnerable dependencies. DAST still has its role for surface-level checks across a wide estate.
What agentic testing adds is a capability the existing stack structurally cannot provide: understanding. Understanding of what the application is trying to do, which users are allowed to do what, and what a sequence of actions means in context. That understanding unlocks the categories of vulnerability that consistently cause the largest incidents.
Business logic
Sequence abuse, approval bypass, discount logic, order and workflow manipulation. Context-dependent by definition, which is why checklist tools cannot reach them.
Broken access control
IDORs, role abuse, tenant escapes, ownership bypass. The single most common source of large-scale data exposure incidents.
Stateful web issues
XSS in context, CSRF variants, session handling, multi-step flows. Require understanding of where in the workflow a request lives.
Attack chains
Combining multiple individually-low-severity issues into one material outcome. The bugs a scanner will triage as noise but an attacker will triage as a path.
07 · How to Adopt It
Start with release testing.
Then move to continuous delta pentesting.
Agentic pentesting does not require a re-architecture of the SDLC. It requires two capabilities turned on in the right order, each of which compounds as the programme matures.
Strategy 1: Release testing
The first and highest-leverage insertion point for agentic testing is the release candidate. Every meaningful release to staging should be pentested autonomously before it is promoted. This is the step that converts "we pentest before major launches" from an aspiration into the default behaviour.
What release testing looks like
01
Run an autonomous pentest on staging for each release candidate
02
Define risk thresholds that gate release on verified critical and high issues
03
Push findings into a fast loop: finding → ticket → fix → retest
04
Keep humans focused on major releases and genuinely novel features
What this changes
01
Initial feedback drops from days or weeks to minutes or hours
02
Evidence replaces alerts as the unit of security communication
03
Security becomes part of the engineering cadence, not a gate outside it
04
Annual pentests refocus on depth, not coverage
Strategy 2: Continuous delta pentesting
Once release testing is stable, the next step is delta pentesting: targeted, change-driven tests that run on every meaningful delta. The insight here is that most code changes don't need a full pentest. They need a pentest of the change, informed by memory of what was tested before.
This is where agentic systems become genuinely cheaper and more accurate than periodic full tests: they don't re-explore the whole application on every run, they reason about what changed and what that change touches.
WHAT CHANGED
Git diff and dependencies
Use source-level signals and black-box recon to detect new routes, permissions, integrations and endpoints introduced by a change.
WHAT IS EXPOSED
Surface update
Map the delta to the existing attack-surface graph instead of rediscovering the entire application every time.
WHAT MATTERS
Targeted plan
Run only the checks relevant to the delta and its adjacent surface, for faster, cleaner feedback that engineers trust.
IS IT EXPLOITABLE
Fast proof
Tie results back to the commit or pull request, so fixes happen in the same context in which the problem was introduced.
Memory and context are what make these tests precise, not noisy. A system with no memory of what it tested yesterday will always default to exhaustive, which is expensive and loud.
08 · Operationalising & Guardrails
Autonomous offensive systems need guardrails, not blind trust.
Running an autonomous system that performs real attacks against production-adjacent environments is not a configuration task. It is a governance exercise with specific prerequisites, integrations and controls.
The prerequisites to get right before turning it on
Prerequisites
01
A staging environment with realistic data and flows
02
Test accounts for every meaningful role in the system
03
Secrets handling and vault integration, not credentials in scope files
04
Traffic visibility and logging sufficient for audit
Integrations
01
CI/CD triggers tied to release and change events
02
Jira and GitHub issue flow with finding-level granularity
03
SARIF/JSON artefacts feeding dashboards and metrics
04
Optional ChatOps notifications to the right on-call
Governance
01
Formal scope approval and audit trails per engagement
02
Rate limits and safe stop conditions encoded in configuration
03
Retention and data handling policy aligned to the target environment
04
Human review required for critical findings before close
The guardrails an autonomous system needs
The question of safety for autonomous offensive testing is not whether the system will ever try to do something unintended. It is whether the controls around it make unintended actions impossible in practice. There are two layers, and both must hold.
Operational guardrails
Strict scope boundaries and explicitly prohibited actions
Production-safe handling, lower concurrency, rate awareness
Evidence-bound reporting and explicit uncertainty labels
Human override and escalation logic on every run
Governance model
Security approves scope and the controls around it
Engineering owns remediation and release response
Legal and leadership define the organisation's risk tolerance
Audit trails make the system observable and reviewable end-to-end
09 · Humans and Programme Maturity
AI cadence, human expertise.
It is tempting, particularly for vendors, to frame autonomous offensive testing as a replacement for human pentesters. That framing is wrong, and it misreads where the cost in most security programmes actually lives.
The most valuable human pentesting hours are spent on novel threat modelling, creative attack chains that require organisational context, and red-team style objectives where the ambiguity of the goal is the point. Those hours are expensive because they are rare, and they are rare because most of a pentester's time gets consumed by work that is not the differentiated part of the job.
Agentic testing's contribution is to absorb the repetitive, stateful, high-frequency work that was eating those hours, and to do it at engineering speed. The human pentester doesn't disappear; their time concentrates on the part of the job that actually requires a human.
Where AI excels
High-frequency validation across a changing attack surface
Repetitive, stateful testing at CI/CD speed
Regression, retest and evidence capture
Coverage of well-understood categories with proof
Where humans still matter most
Novel threat modelling and unusual attack creativity
Complex exploit chains across business and organisational context
Risk acceptance, governance judgement and communication
Red-team objectives where ambiguity is the whole point
The real model is not human or AI. It is human expertise amplified by AI cadence.
This is bigger than a better test
Most pentest programmes are limited by follow-through, not by the quality of the test itself. The engagement ends, the PDF lands in an inbox, and the organisational memory of what was tested and what was fixed decays fast. Next year's test rediscovers much of what last year's test already found.
A mature AppSec programme treats offensive validation as an operational capability, not a point-in-time service. That shift only works when the three stages of a pentest programme, preparation, testing and follow-up, are treated as equally important, and when each stage produces artefacts the next stage can use without losing information.
STAGE 01
Preparation
Governance, scoping, asset understanding and test drivers. The work that determines whether the test will produce anything useful.
STAGE 02
Testing
Methodology, execution quality, evidence capture and reporting. The work the industry spends most of its attention on.
STAGE 03
Follow-up
Remediation, retest, root cause, knowledge retention, and measurable improvement over time. The work most programmes underinvest in, and the work that defines real maturity.
10 · Takeaways
Four things to carry forward.
01
Traditional shift-left is incomplete
Moving scanners earlier in the pipeline does not move attacker-like validation earlier. The categories that cause breaches are the categories pattern-matching tools cannot reach, and no amount of earlier scanning closes that gap.
02
Agentic testing is about reasoning
State, intent, adaptation and proof are what separate agentic testing from 'better scanning'. Any system claiming the former without demonstrating the latter should be judged against the five-criteria rubric and nothing less.
03
The operating model matters
Scope → Recon → Plan → Execute → Report → Retest is how the approach becomes repeatable inside the SDLC. The workflow is the product; the AI is the enabler.
04
Humans still matter
Use AI to compress the feedback loop and absorb the repeatable work. Keep humans on the parts of the job that require judgement, accountability and creativity, which is most of what matters.
The future of AppSec is not more alerts. It is continuous offensive validation, close to the code, close to the change, and close to the decision to ship.
Ready to Shift Attacker-Like
Validation Left?
Shinobi delivers autonomous penetration testing that mirrors the offensive chain of reasoning a skilled tester uses, at the cadence modern engineering requires. Every finding is proven. Every report is actionable. Every retest is on demand.
Request a Private EvaluationContact · info@shinobi.security